【笔记】通过算力云云服务器训练AI实现音色转换
前言
通过算力云云服务器训练AI实现音色转换
选购云服务器
- 在https://www.autodl.com选购
容器实例->镜像选择社区镜像->innnky/so-vits-svc/so-vits-svc-v4-Webui / v10
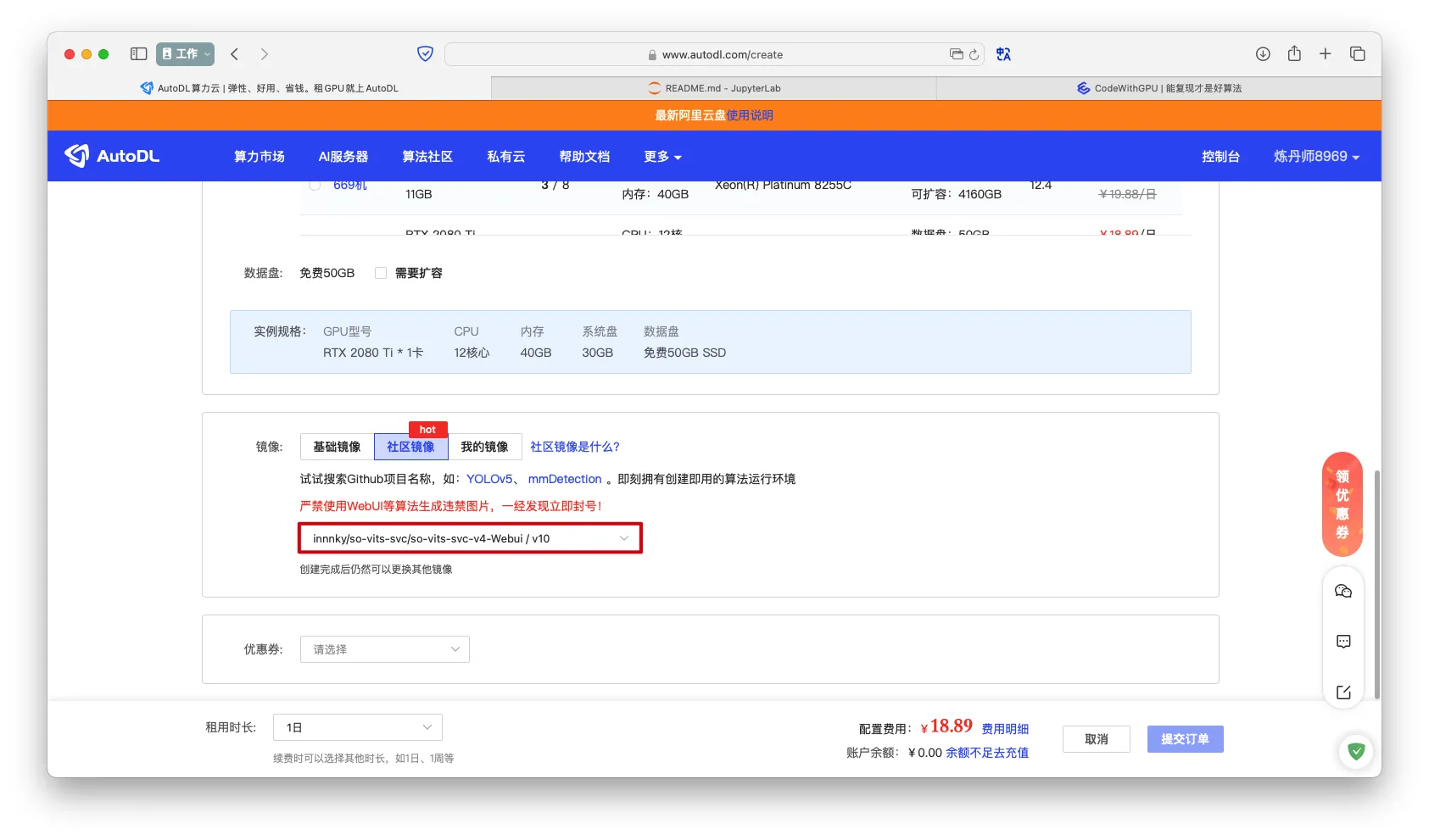
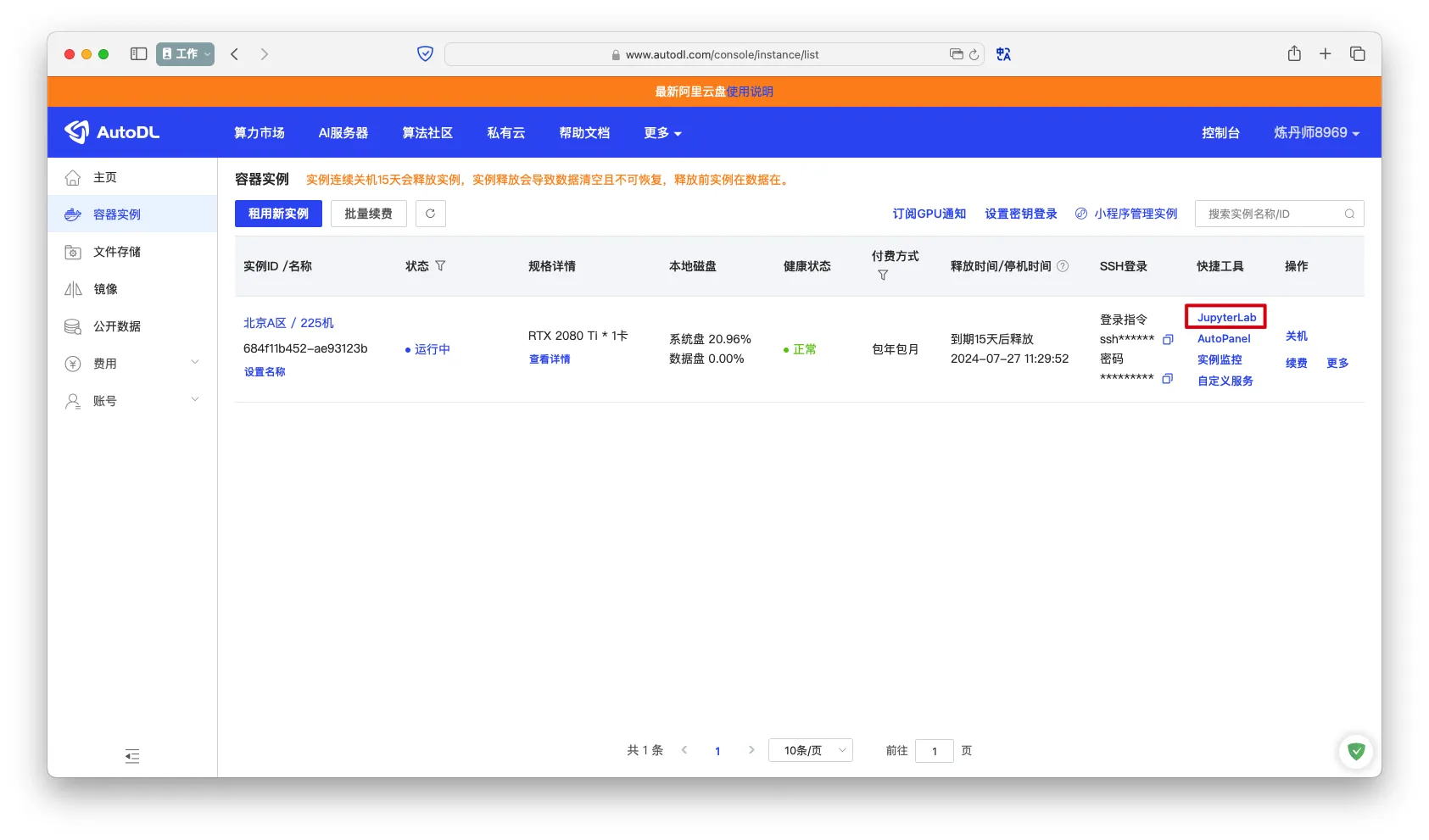
- 付款后点击
JupyterLab进入控制台
准备声音素材
- 要求总计2小时以上的声音素材
- 需人生干音作为声音素材,尽可能的去除噪音和混响
- 声音文件格式需为
.wav格式 - 声音文件需切片,每个切片时长最长15秒
- 切片后的声音文件放置在
dataset_raw目录下
1 | + dataset_raw |
上传声音素材
- 准备
upload.zip
1 | + upload.zip |
- 进入
dataset_raw目录
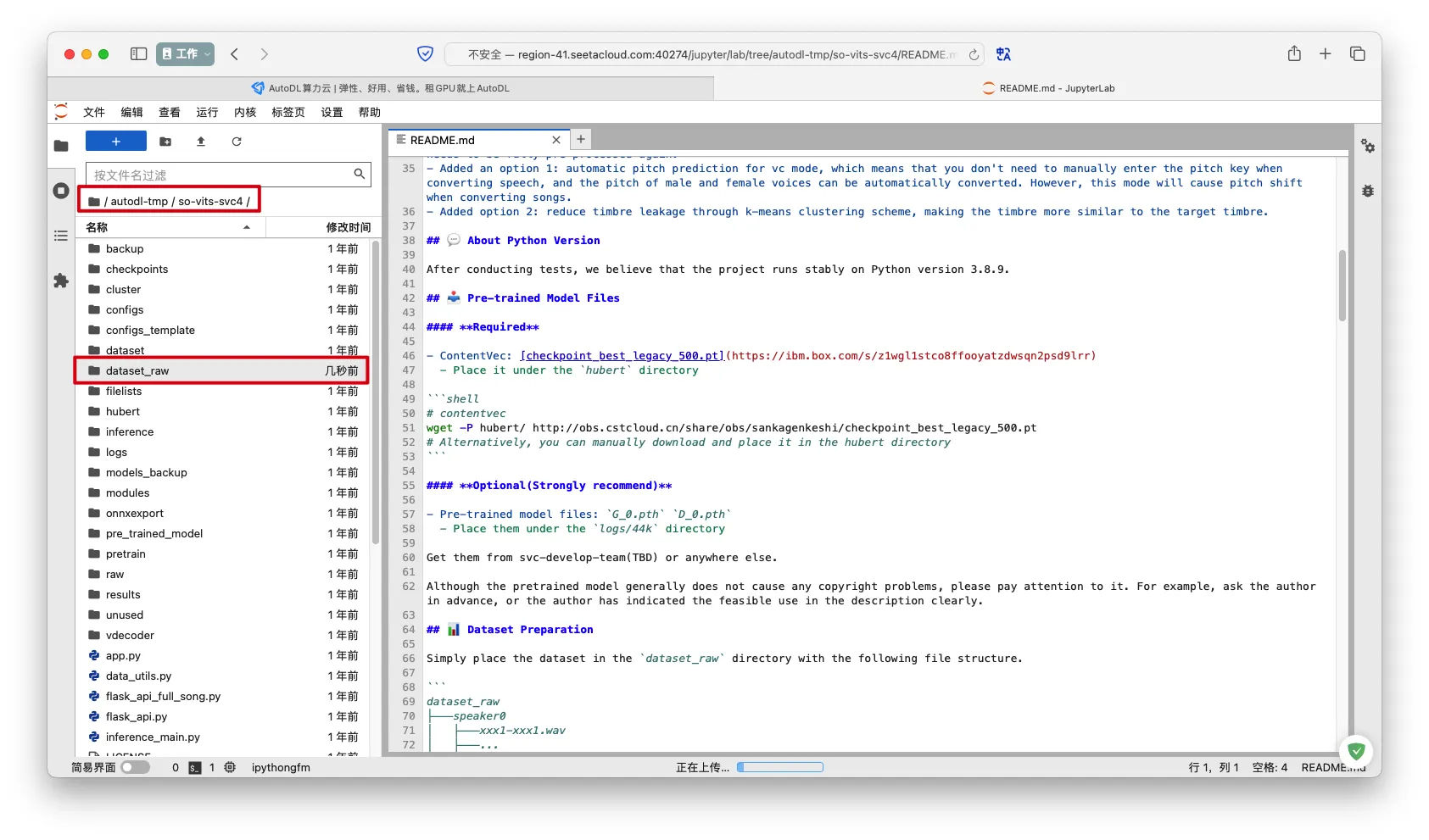
- 点击上传按钮,上传
upload.zip
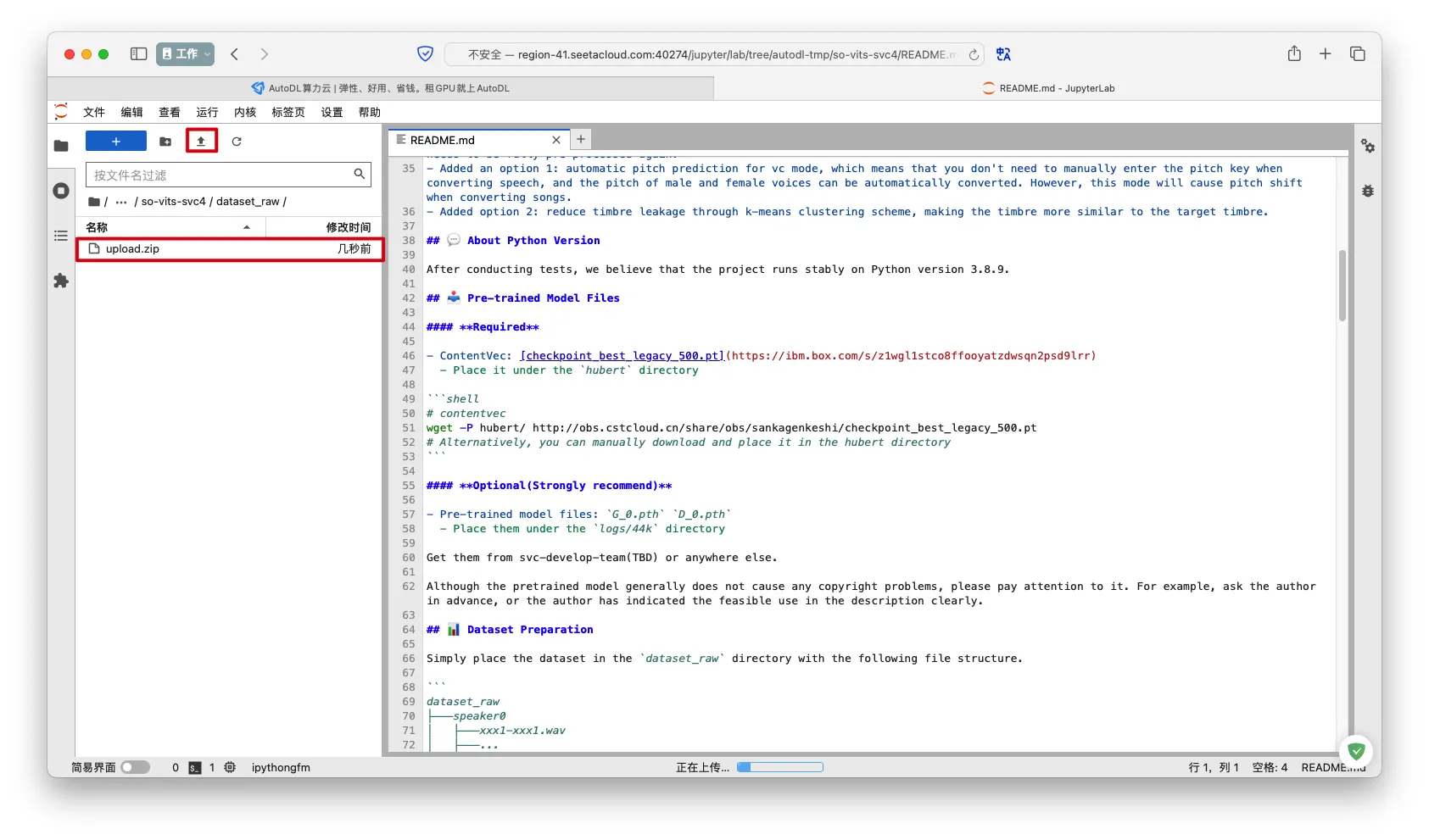
- 打开终端
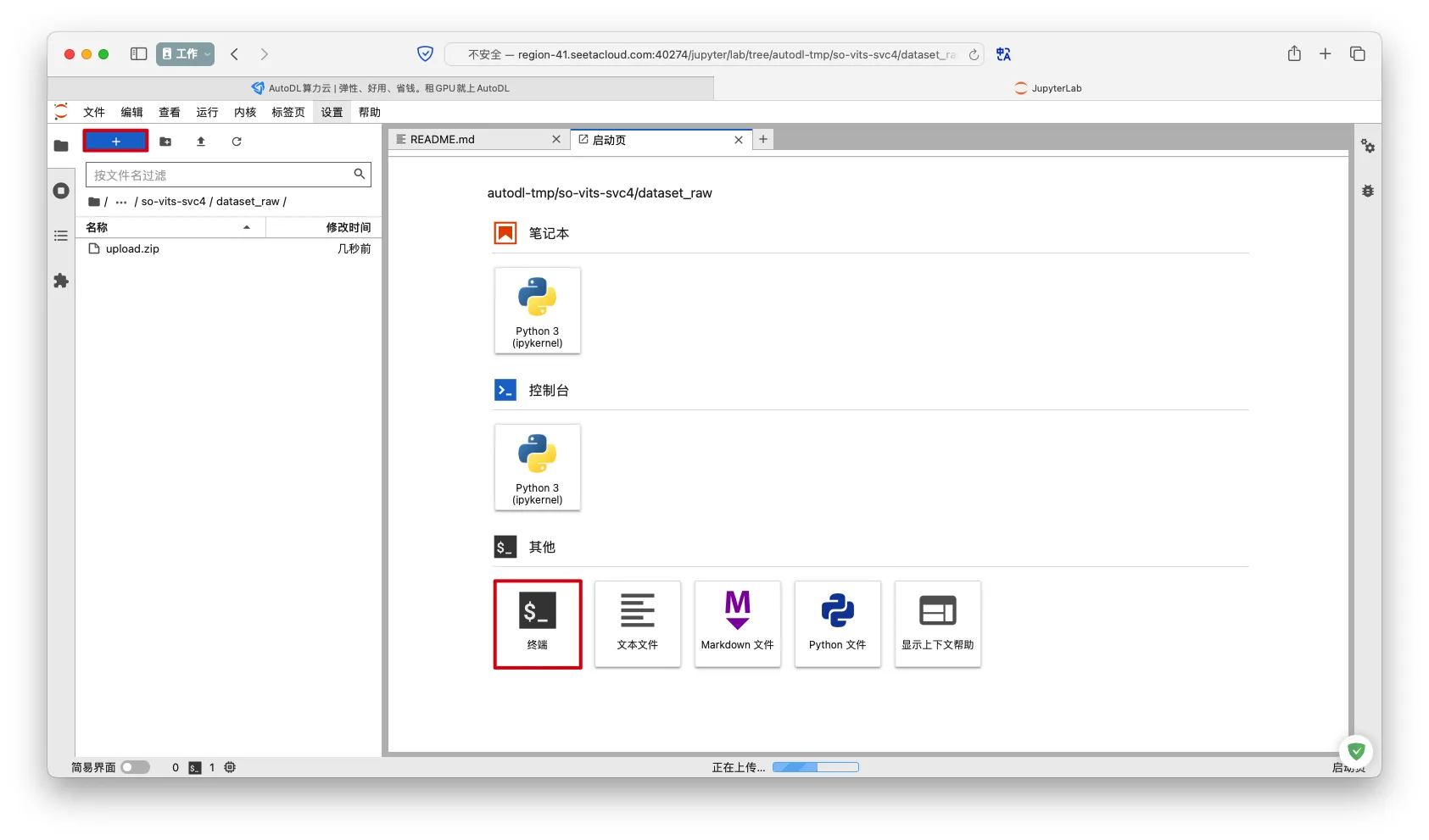
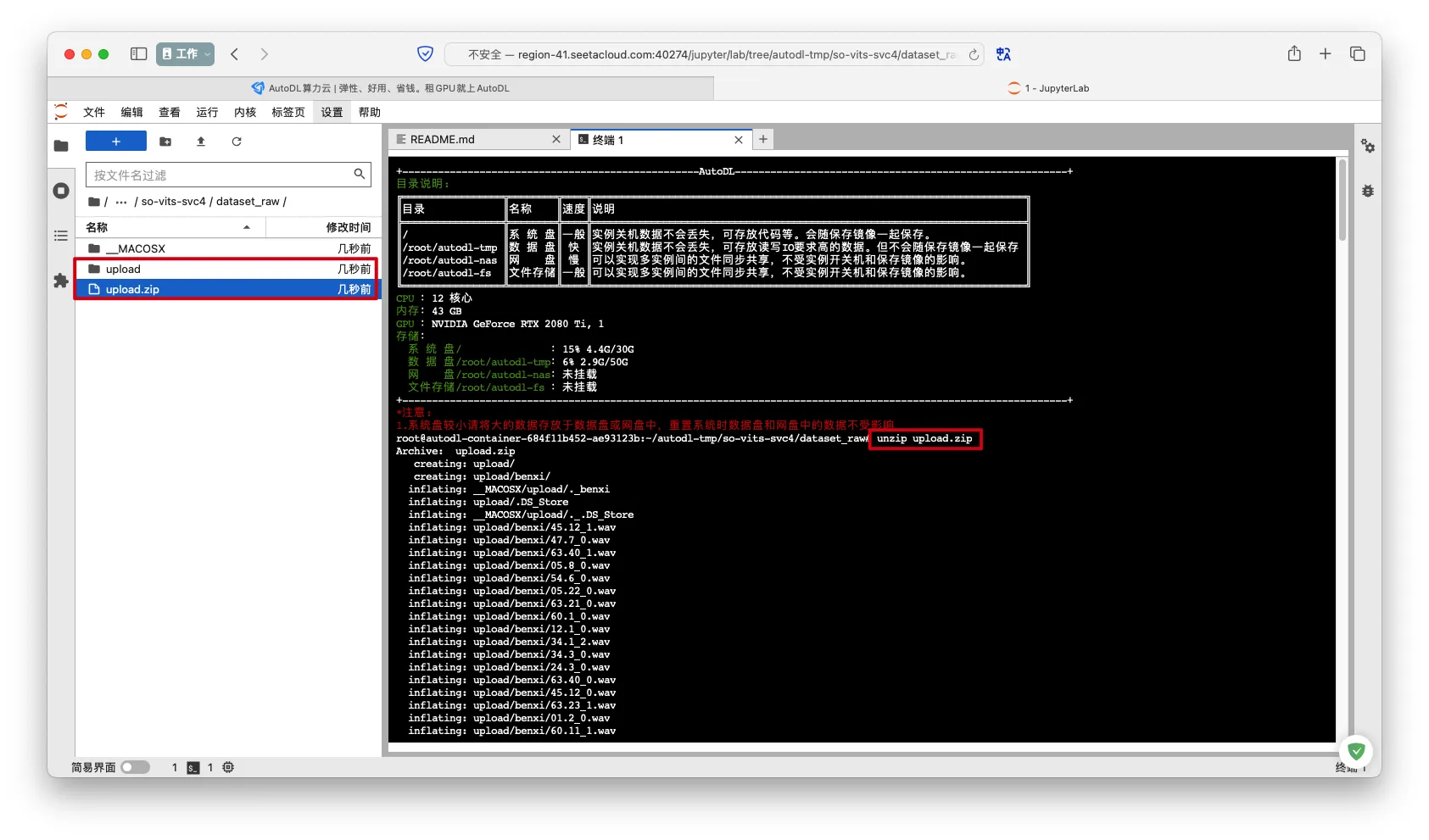
- 解压,并删除无关文件
如果是MacOS上打包的zip文件,解压后需要清理__MACOSX目录和.DS_Store文件
如果打包的zip文件包含多层目录层级,需要清理目录层级保持只有一层目录
1 | unzip upload.zip |
生成配置文件
1 | python preprocess_flist_config.py --speech_encoder vec768l12 |
WebUI
- 在项目根目录打开终端
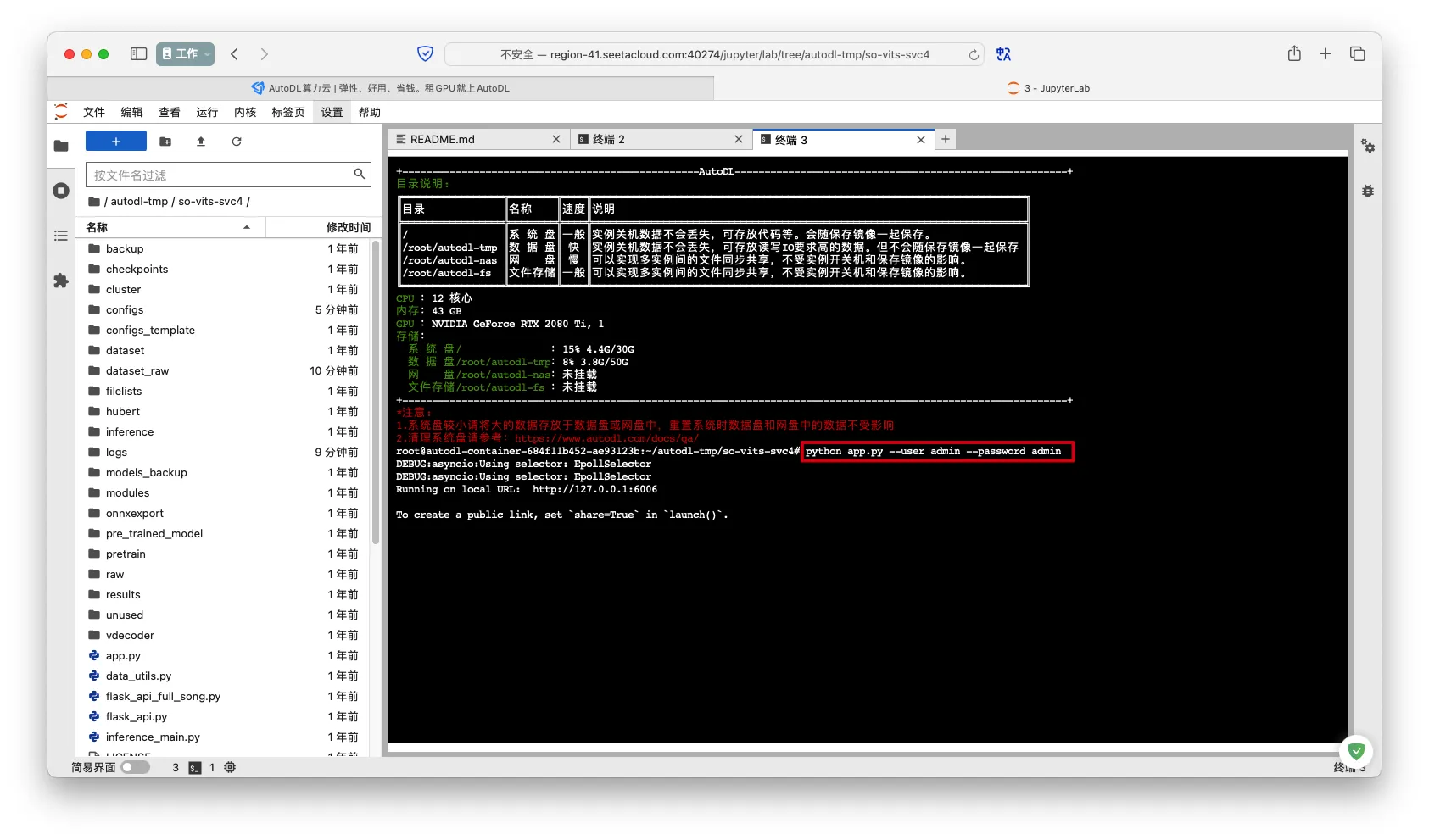
- 运行WebUI
--user <username> --password <password>:定义WebUI访问用户名和密码
1 | python app.py |
开启WebUI公网访问
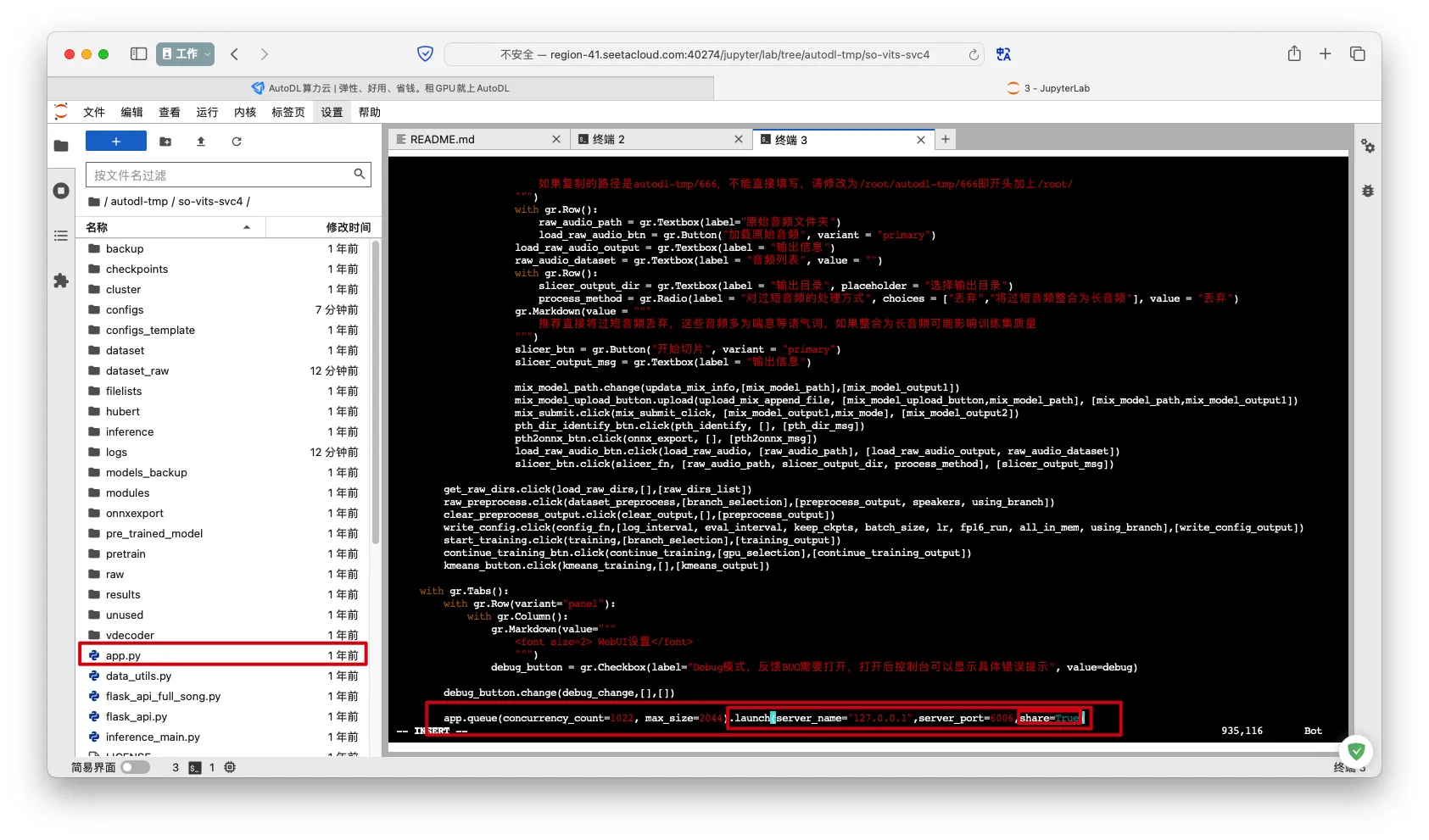
- 修改
app.py文件中的lunch()函数,添加share=True参数
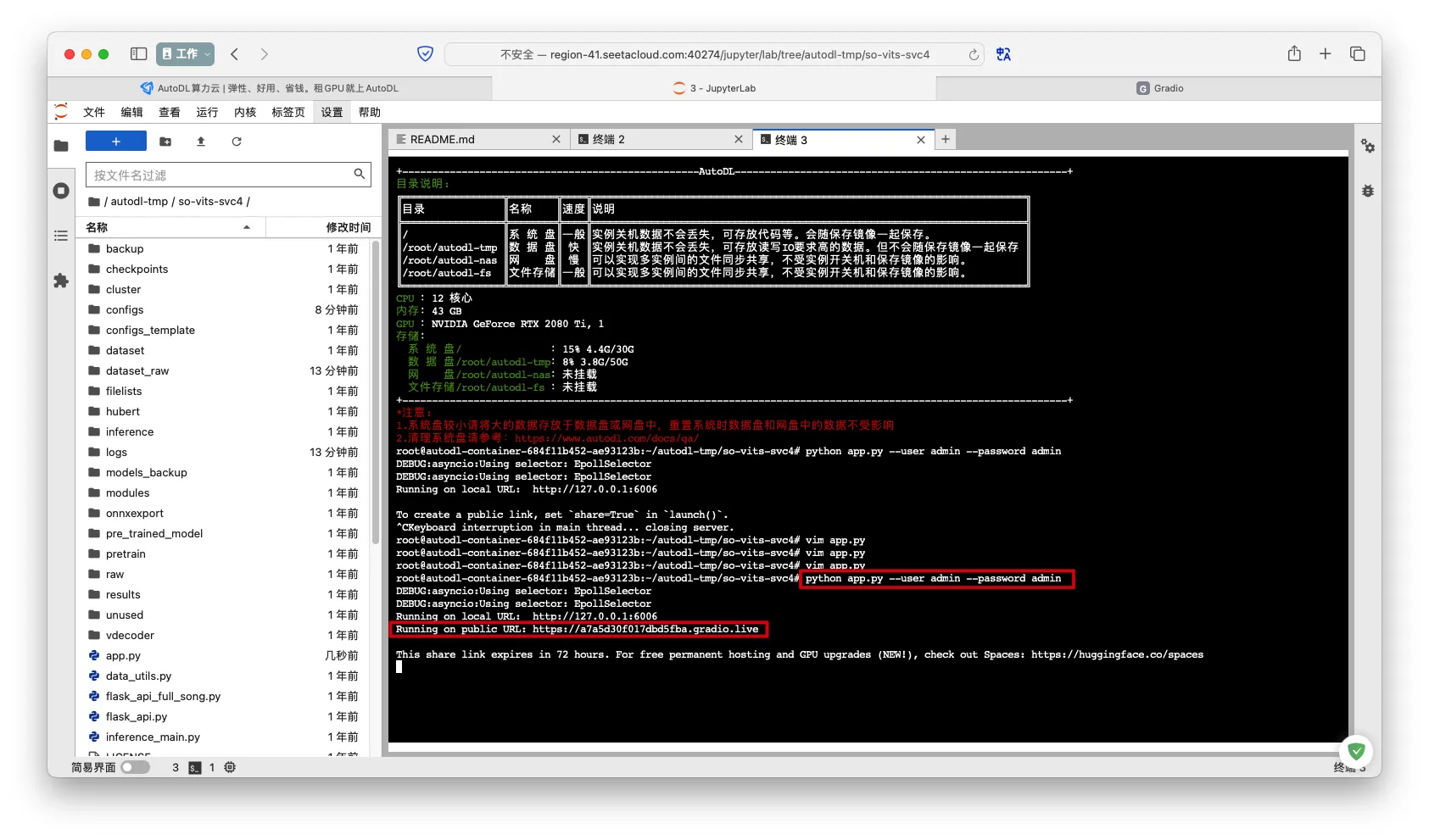
- 运行WebUI
1 | python app.py |
训练
通过命令训练
- 在项目根目录打开终端
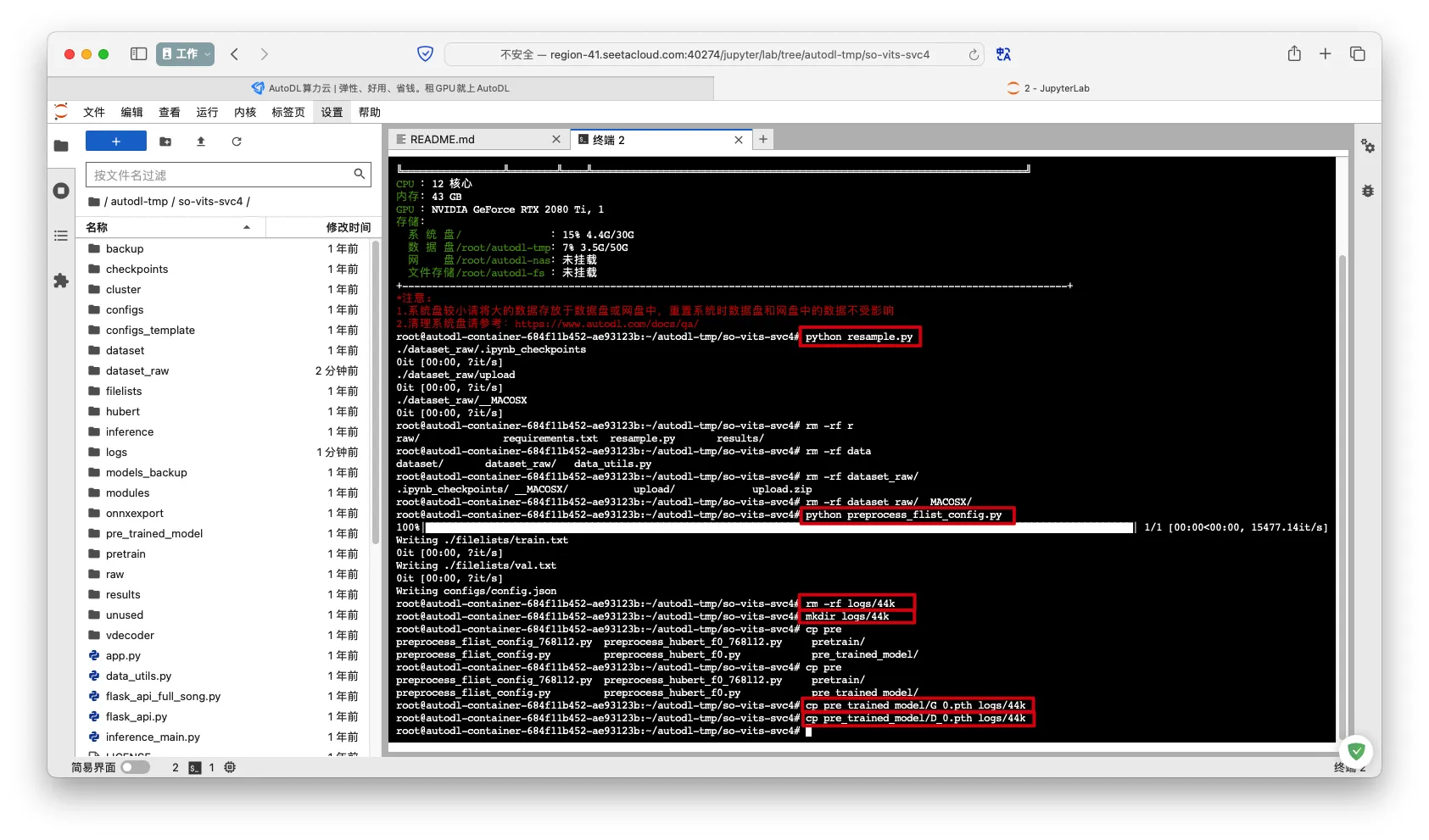
- 准备预处理模型
1 | python resample.py |
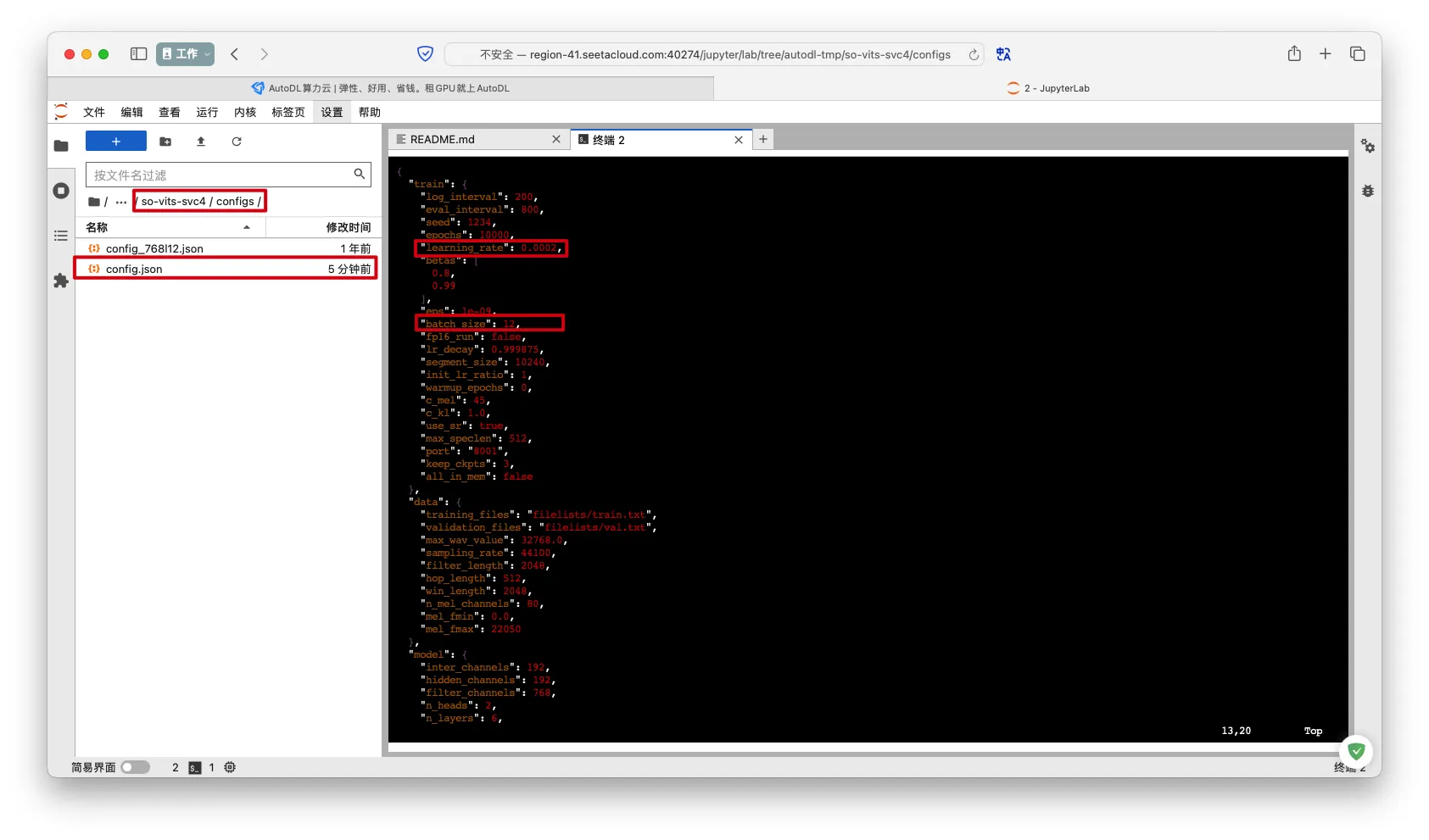
- 修改配置文件
configs/config.json,learning_rate和patch_size可以根据实际情况成比例提高或降低
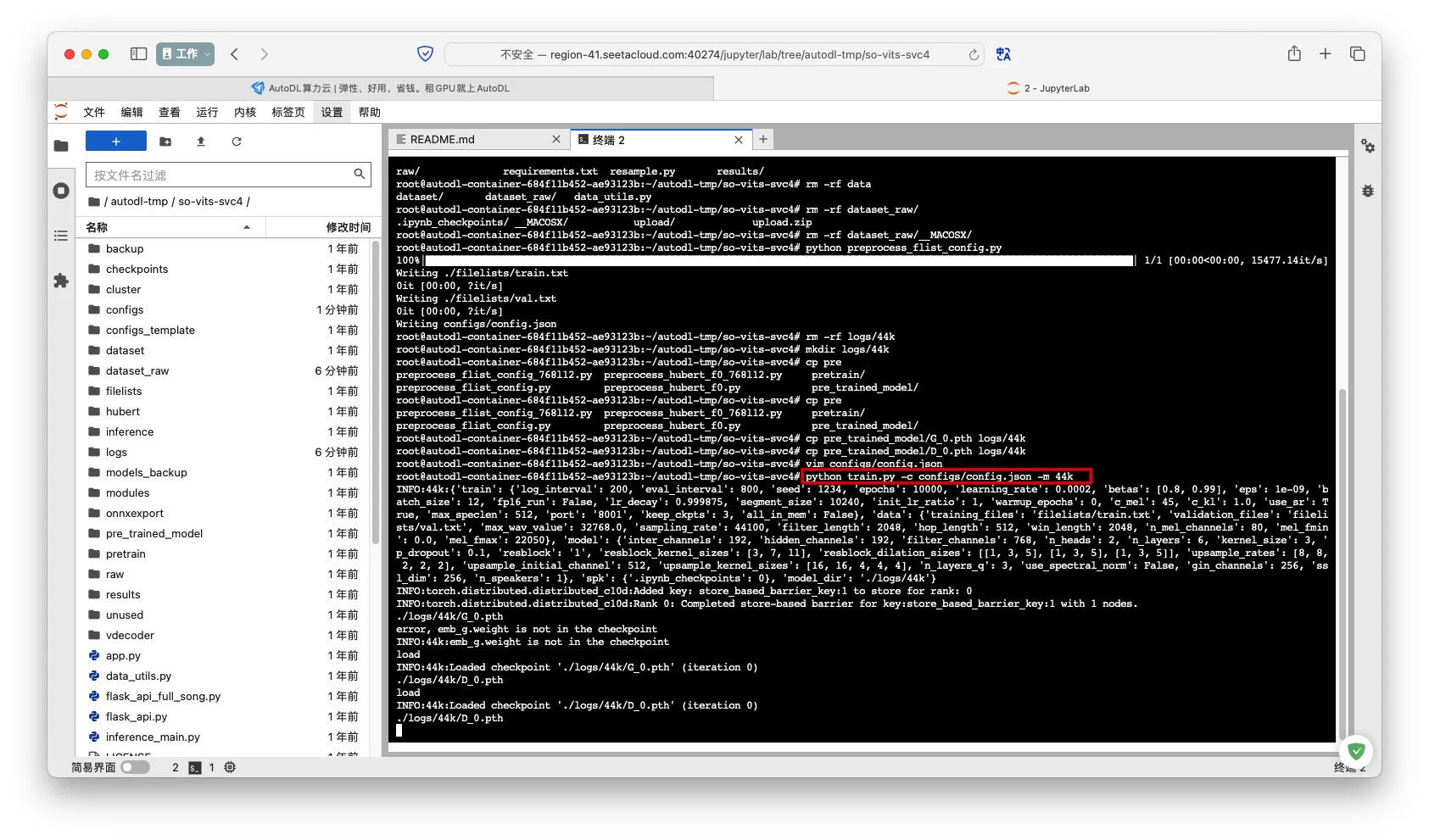
- 开始训练
1 | python train.py -c configs/config.json -m 44k |
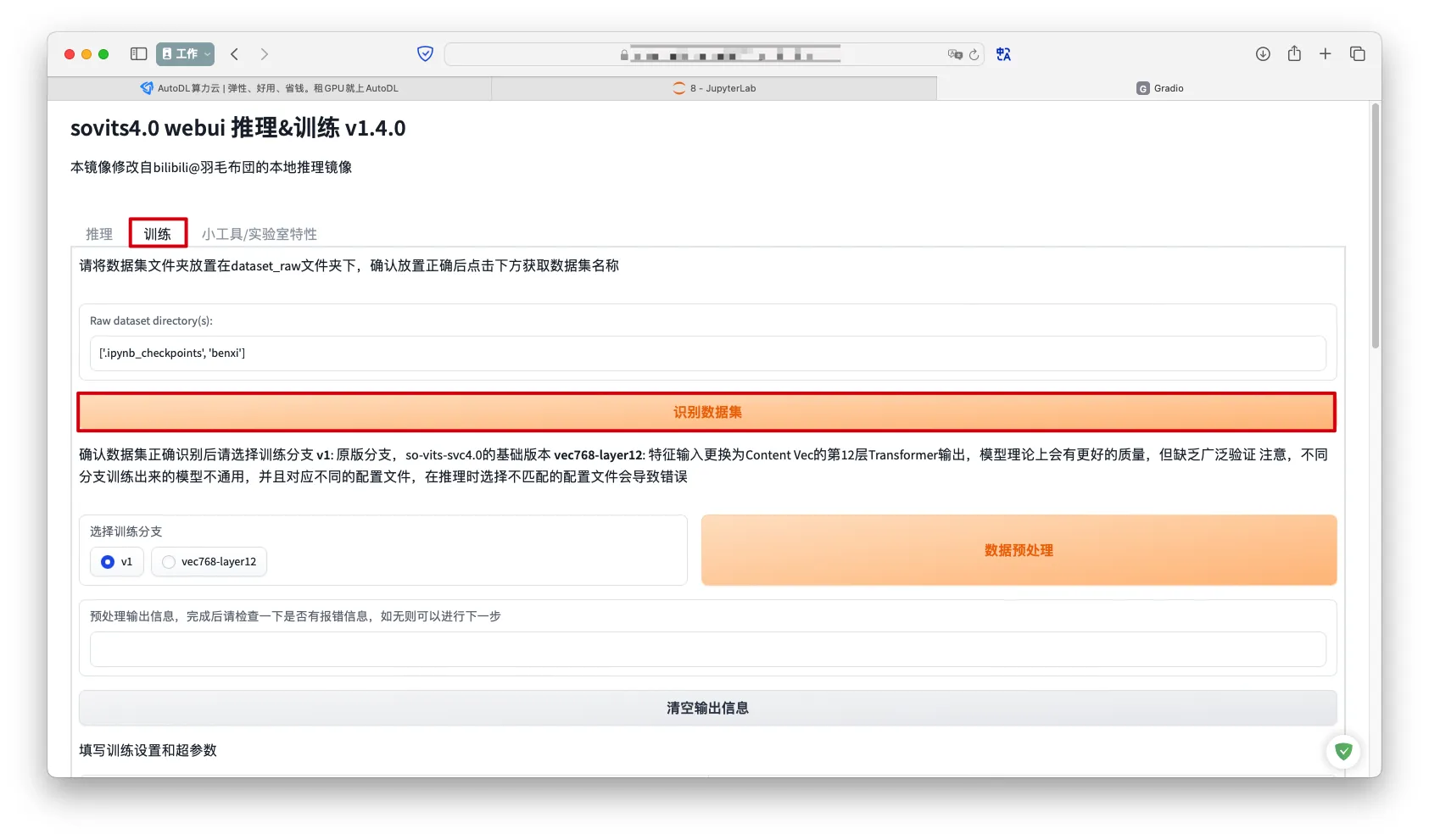
通过WebUI训练
训练->识别数据集
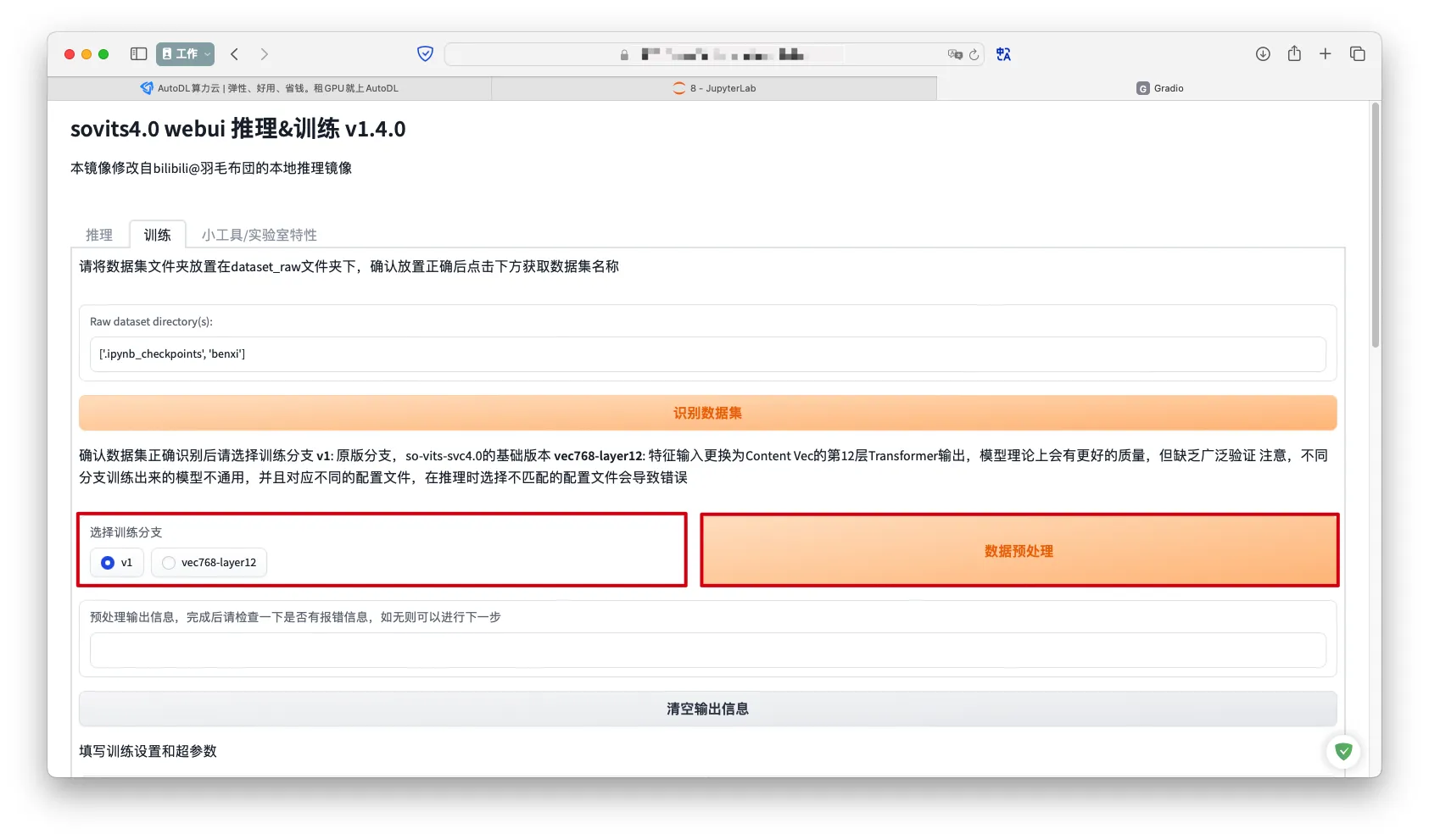
- 选择训练分之->
数据预处理
写入配置文件
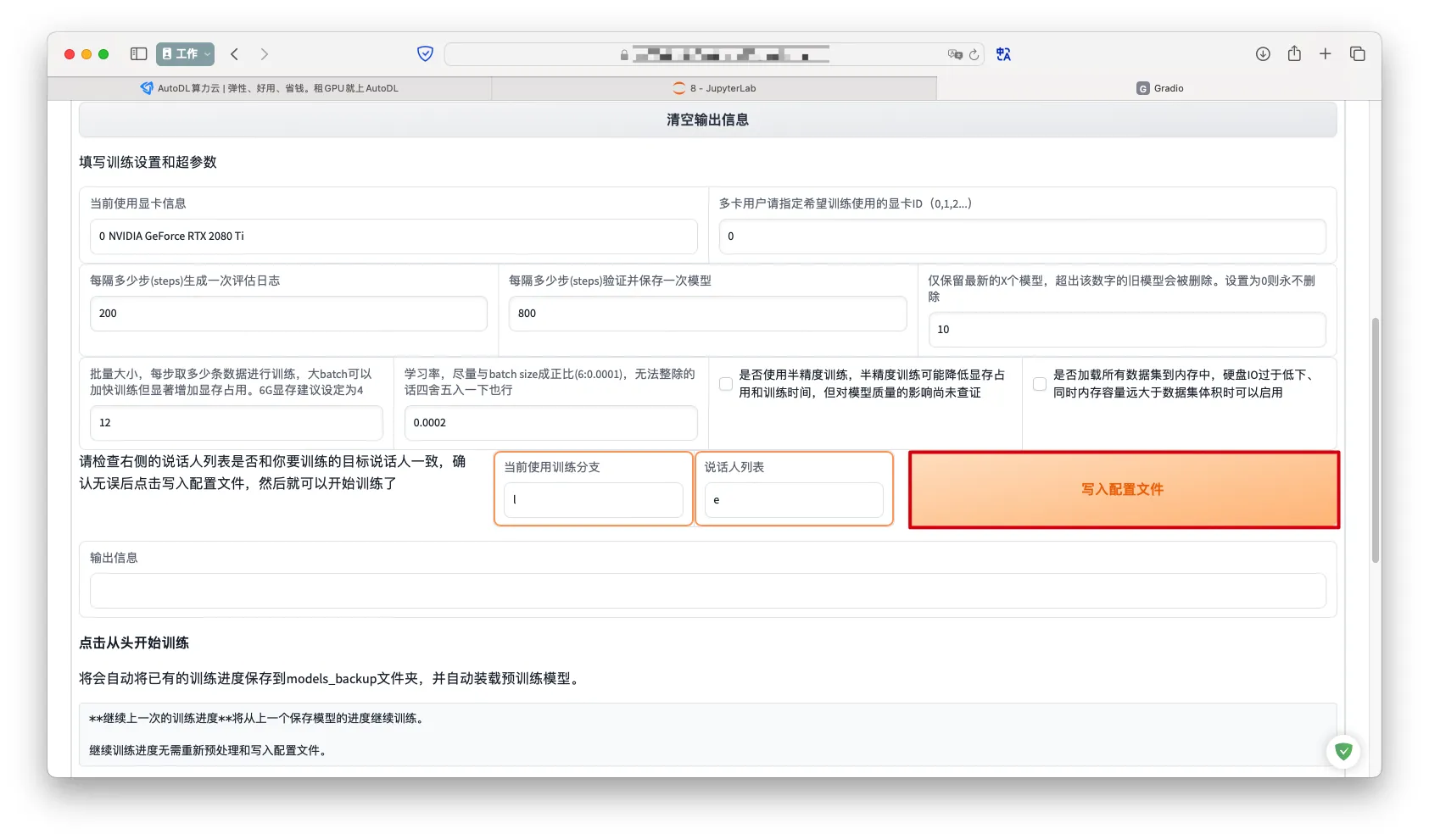
从头开始训练->根据提示执行命令
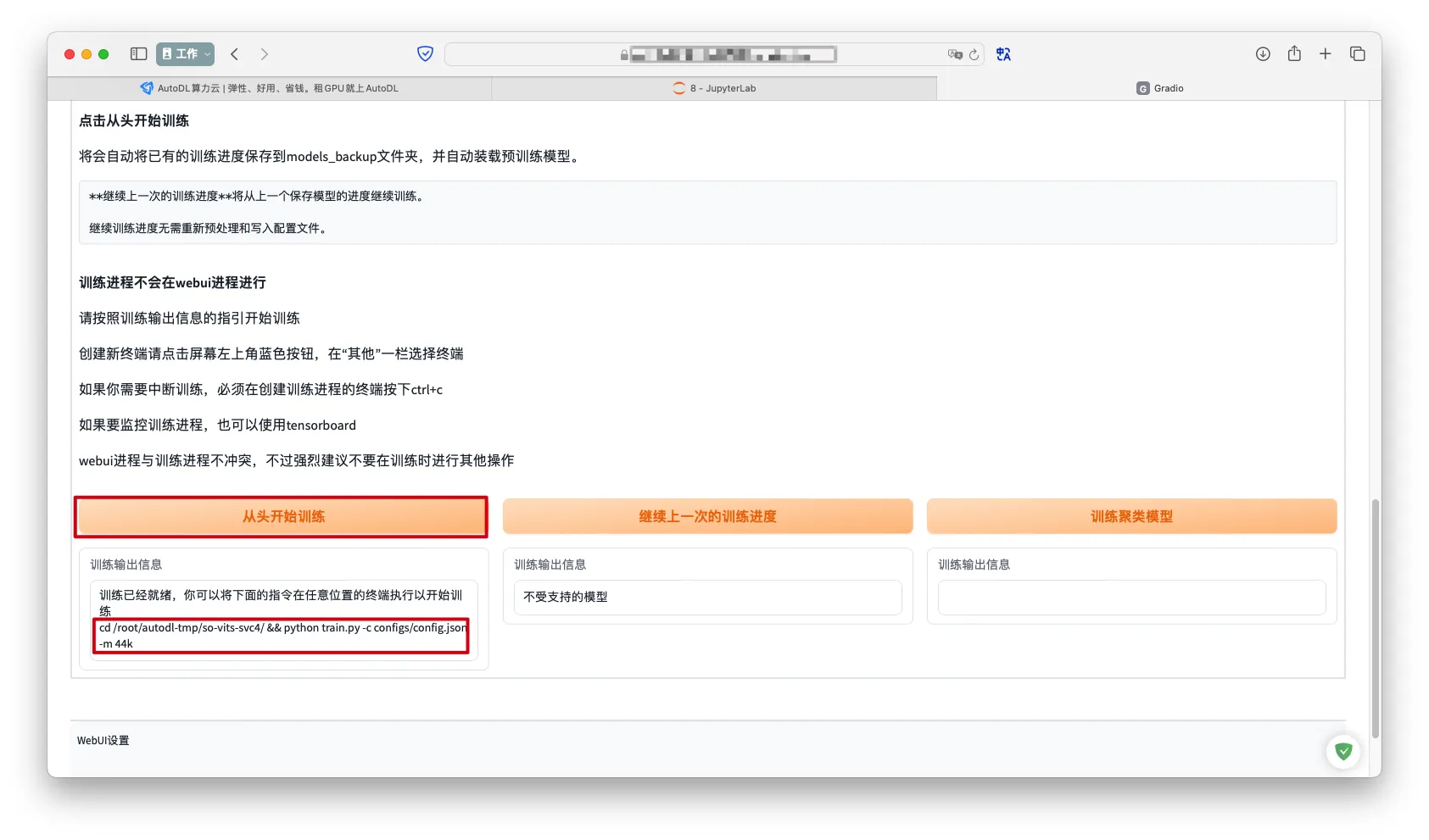
备份训练后的模型
停止训练后才会生成以
00.pth结尾的模型文件备份
logs/44k目录下的config.json文件和G_x00.pth文件
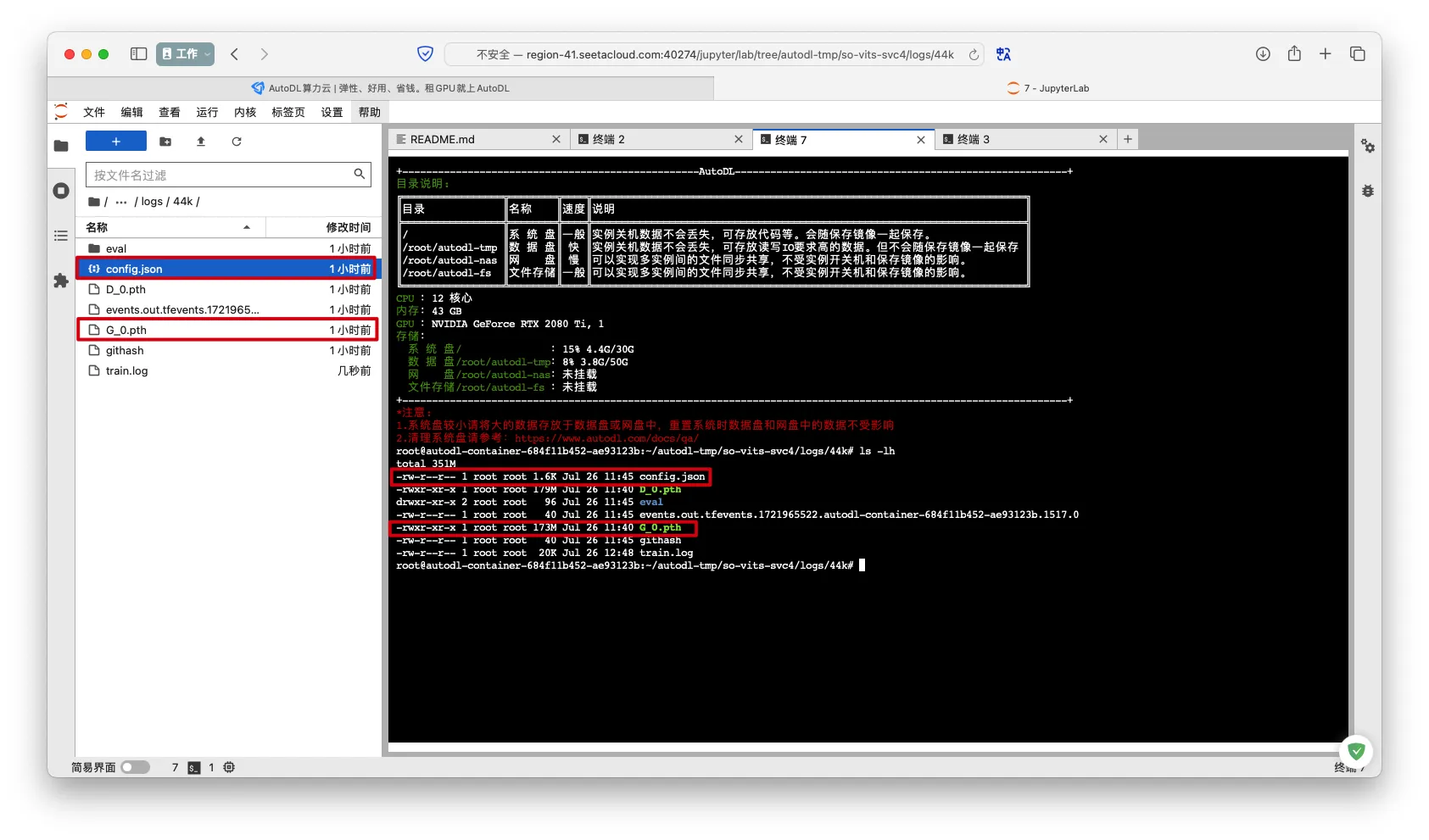
- 训练时程序会自动检测以
00.pth结尾的模型文件,自动判定是否需要继续训练
推理
还原备份的模型(可选)
G_xxx.pth文件放到logs/44k目录下config.json文件放到configs目录下
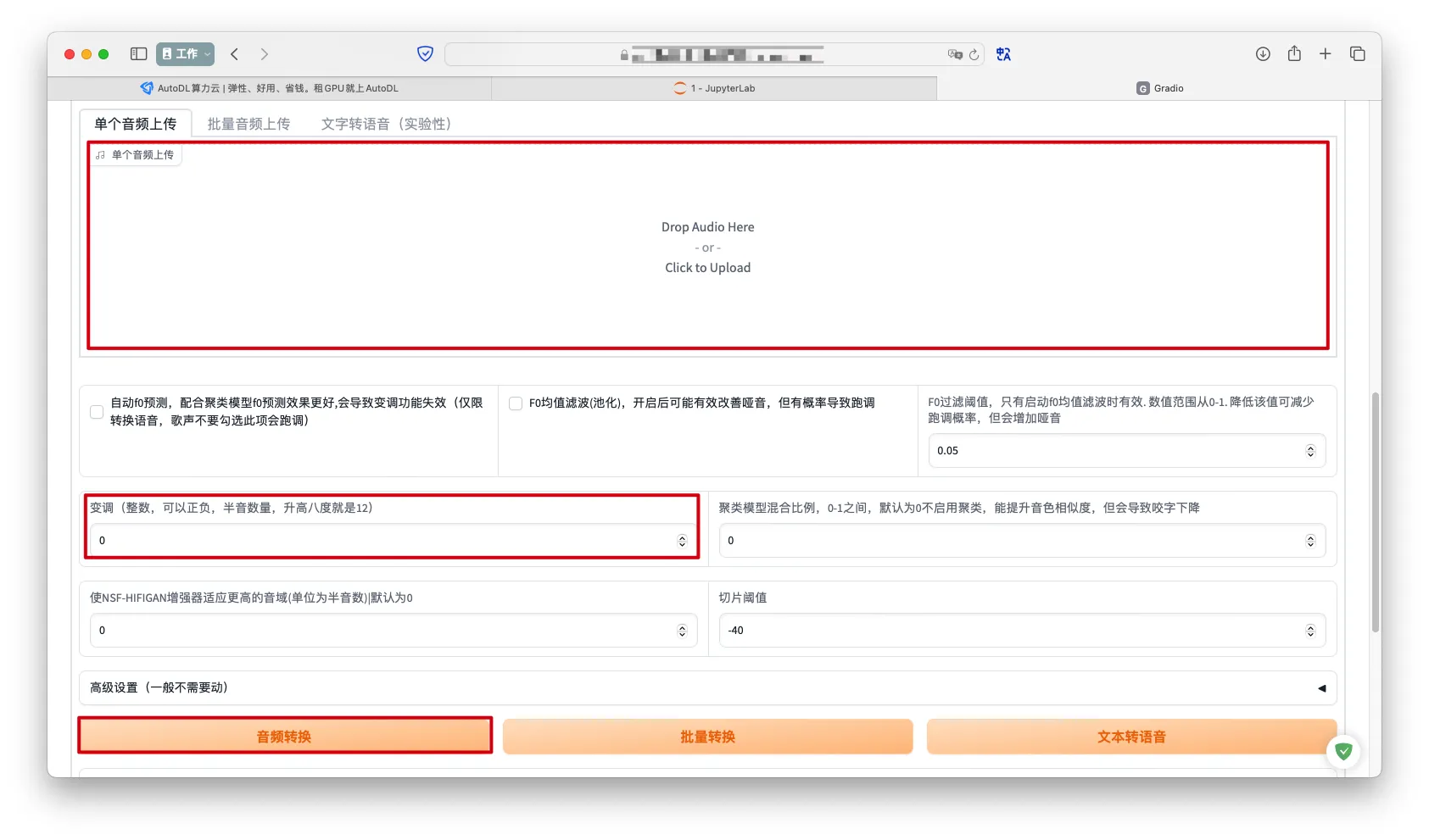
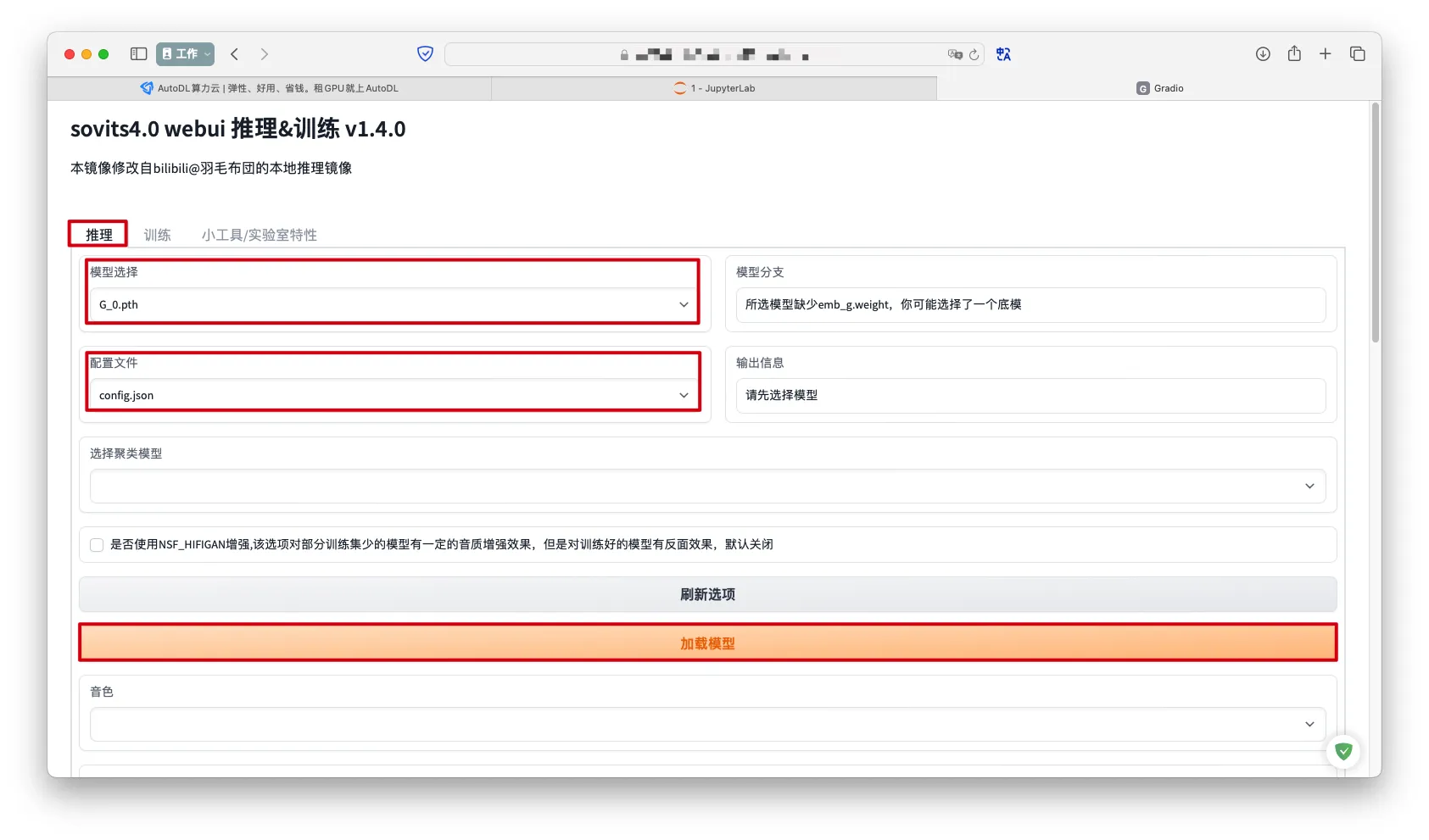
通过WebUI推理
推理->选择模型选择和配置文件->加载模型
如果有聚类模型也可以进行选择
- 上传原音色的文件->设置变调->
音频转换
变调配置参考男转男、女转女:0
男转女:[5,8]
女转男:[-5,-8]