【笔记】Windows通过整合包训练AI实现音色转换
前言
Windows通过整合包训练AI实现音色转换
下载整合包
1 | certutil -urlcache -split -f https://github.com/Feiju12138/so-vits-svc/releases/download/archive/so-vits-svc.zip.001 |
运行WebUI
运行
启动webui.bat批处理文件等待启动完成
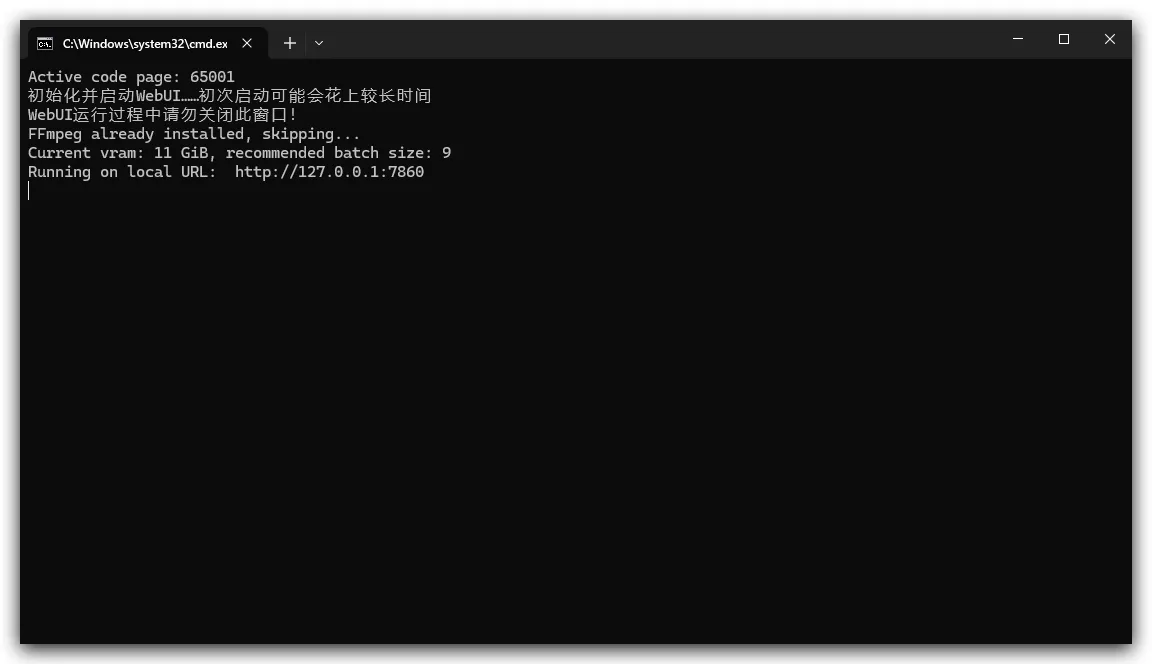
- 启动完成后自动打开浏览器跳转到http://127.0.0.1:7860
准备声音素材
- 要求总计2小时以上的声音素材
- 需人生干音作为声音素材,尽可能的去除噪音和混响
- 声音文件格式需为
.wav格式 - 声音文件重采样为44100Hz单声道
- 声音文件需切片,每个切片时长为5~15秒
- 切片后的声音文件放置在
dataset_raw目录下
1 | + dataset_raw |
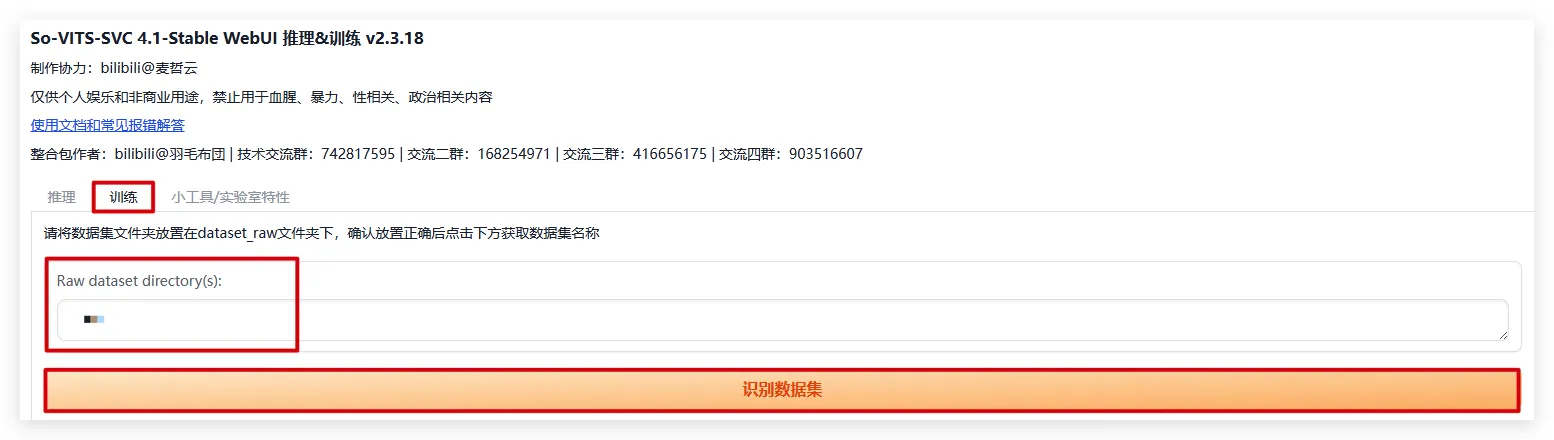
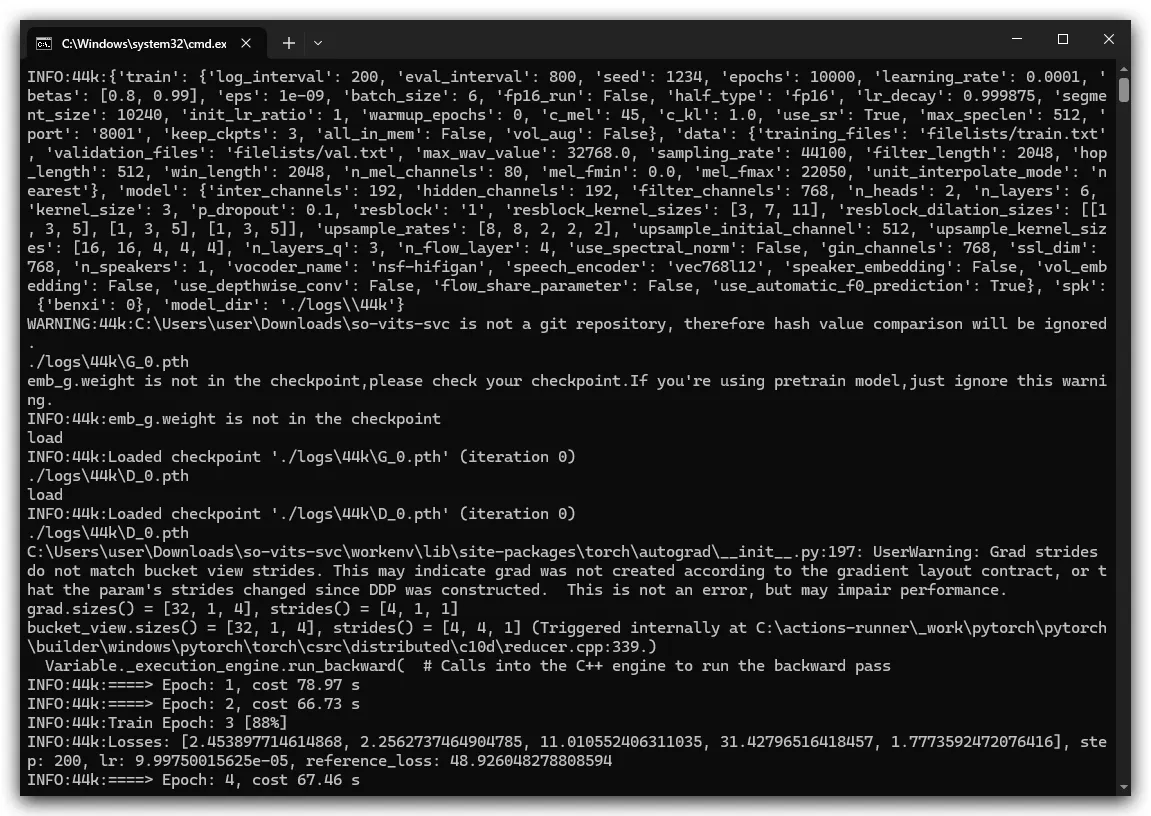
训练
训练->点击识别数据集,等待出现角色名
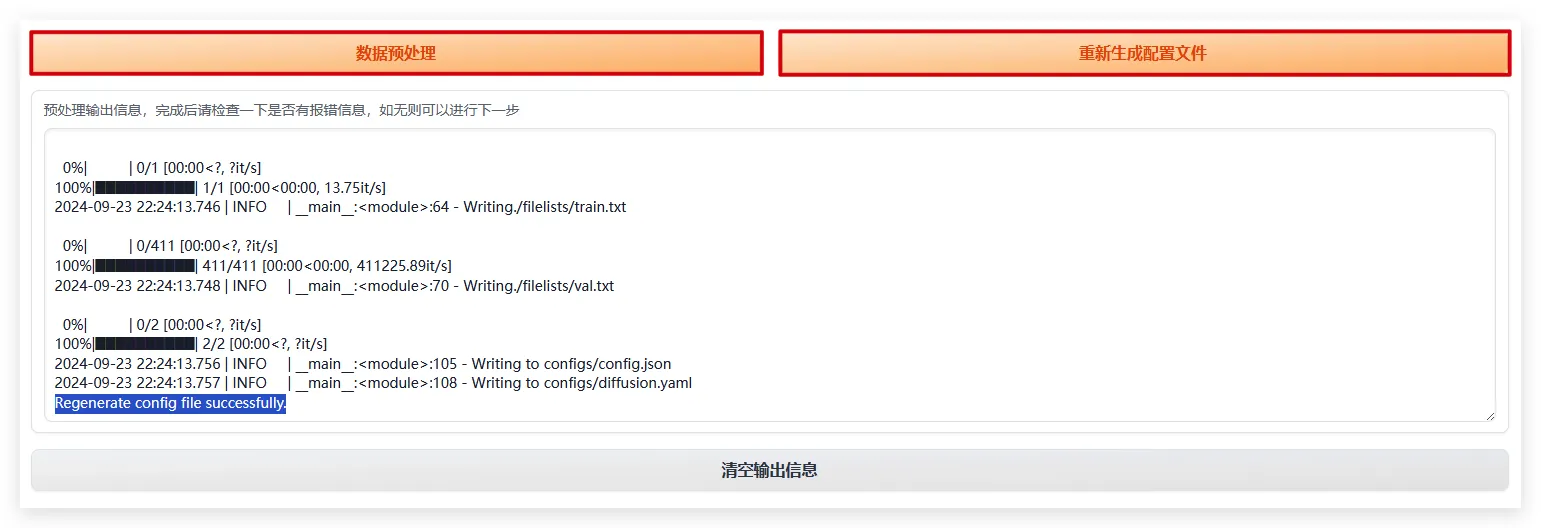
- 点击
数据预处理等待跑码完成->点击重新生成配置文件等待出现Regenerate config file successfully.表示跑码完成
- 出现
Epoch和step即为正在训练
每隔8000步会自动保存一次模型,保存在logs\44k文件夹下
默认最多保存3个模型,如果超出3个会自动清理旧的创建新的
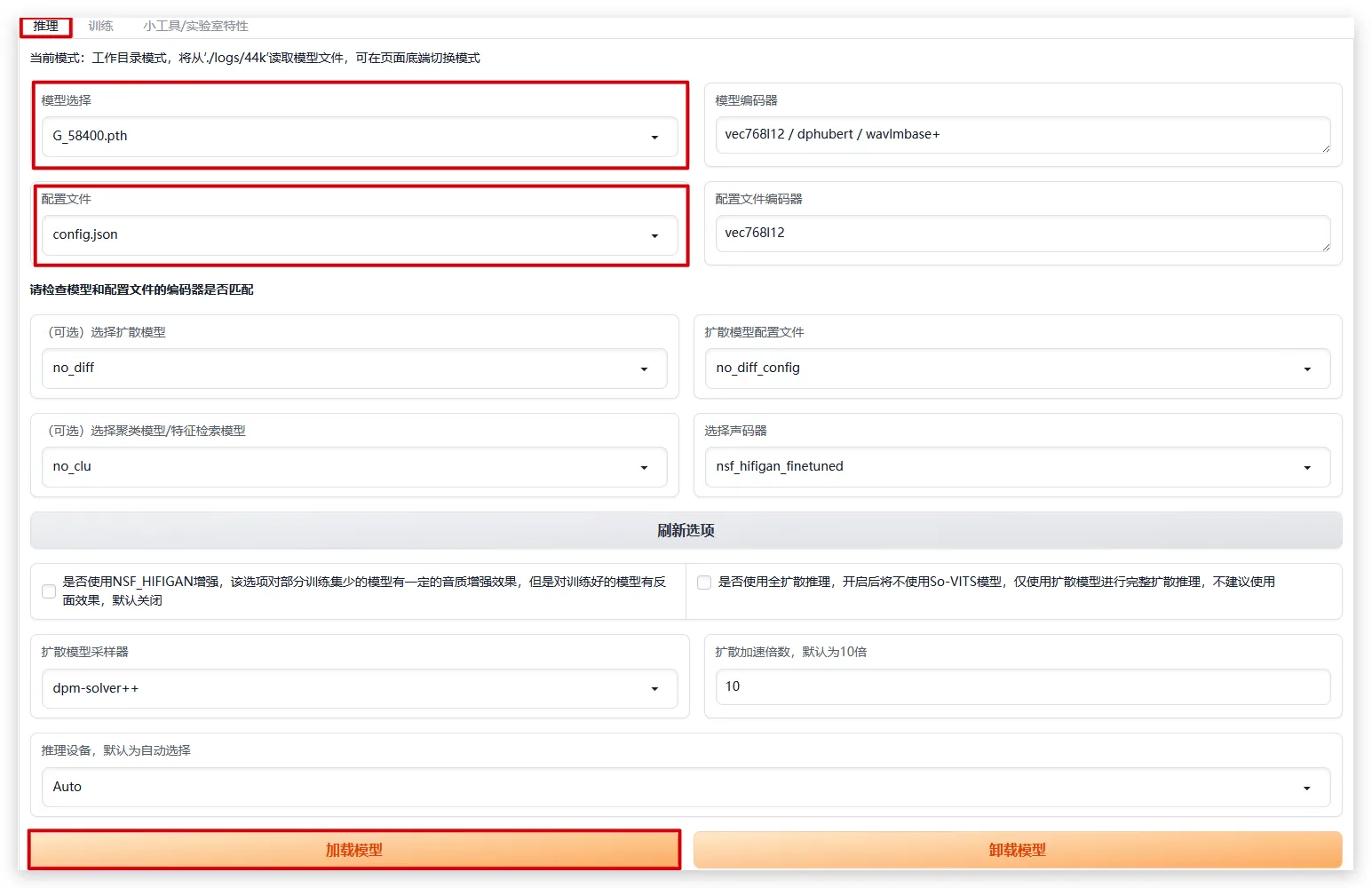
推理
加载模型
推理->选择模型选择和配置文件->加载模型
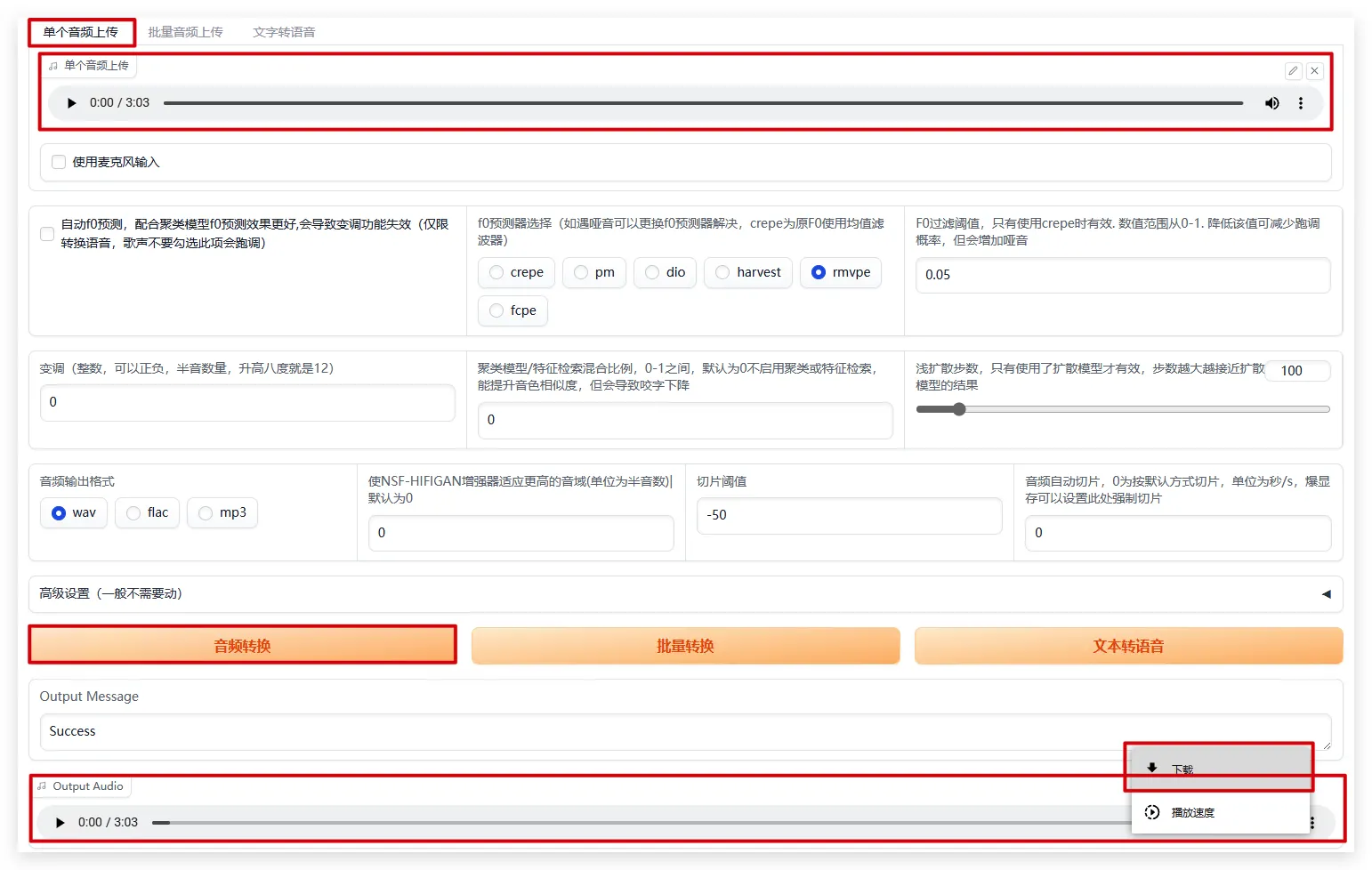
音频转换
单个音频上传->上传转换前的音频->音频转换->得到转换后的音频